В основі побудови сучасної експериментальної психології лежить формула К. Левіна- поведінка є функція особистості та ситуації:
B = f (P; S).
Необіхевіористи ставлять у формулу замість Р(Особистість) Про (організм), що точніше, якщо вважати випробуваними не тільки людей, а й тварин, а особистість редукувати до організму.
Як би там не було, більшість фахівців з теорії психологічного експерименту, зокрема Макгіган, вважають, що у психології існують два типи законів:
1) «стимул-відповідь»;
2) «організм-поведінка».
Перший тип законіввиявляється під час експериментального дослідження, коли стимул (завдання, ситуація) - це незалежна змінна, а залежна змінна - відповідь випробуваного.
Другий тип законівє продуктом методу систематичного спостереження та виміру, оскільки властивостями організму керувати за допомогою психологічних засобів не можна.
Чи існують «перетину»? Зрозуміло. Адже у психологічному експерименті найчастіше враховується вплив про додаткових змінних, більшість із яких є диференціально-психологічними характеристиками. Отже, є сенс додати до списку та «системні» закони,що описують вплив ситуації на поведінку особистості, що має певні властивості. Але в психофізіологічних та психофармакологічних експериментах можна впливати на стан організму, а в ході формуючого експерименту - цілеспрямовано та незворотно змінювати ті чи інші властивості особистості.
У класичному психологічному поведінковому експерименті встановлюється функціональна залежність виду
R = f(S) ,
де R- відповідь, a S- Ситуація (стимул, завдання).
Змінна S систематично варіюється, а зміни відповіді, що детермінуються нею, випробуваного фіксуються. У ході вивчення проявляються умови, за яких випробуваний поводиться тим чи іншим чином. Результат фіксується у формі лінійної чи нелінійної залежності.
Інший типзалежностей символізується як залежність поведінки від особистісних властивостей чи станів організму випробуваного:
R = f(О) або R = f(Р).
Досліджується залежність поведінки випробуваного від того чи іншого стану організму (хвороби, втоми, рівня активації, фрустрації потреб тощо) або від особистісних властивостей (тривожності, мотивації тощо). Дослідження проводяться за участю груп людей, що відрізняються за цією ознакою: якістю або актуальним станом.
Звичайно, ці дві суворі залежності є найпростішими формами відносин між змінними. Можливі складніші залежності, які встановлюються в конкретному експерименті, зокрема, факторні плани дозволяють виявити залежності виду R = f (S 1 , S 2), коли відповідь випробовуваного залежить від двох параметрів ситуації, що варіюються, а поведінка є функцією стану організму і середовища.
Зупинимося на формулі Левіна. У загальній формі вона виражає ідеал експериментальної психології: можливість передбачити поведінку конкретної особистості певної ситуації. Змінна «особистість», що входить до складу цієї формули, навряд чи може розглядатися лише як «додаткова». Традиція необіхевіоризму пропонує використовувати термін «проміжна» змінна. Останнім часом за такими «змінними» – властивостями та станами особистості – закріпився термін «змінна-модератор», тобто посередник.
Розглянемо основні можливі варіанти відносин між залежними змінними.
Існує, як мінімум, шість видів, зв'язку змінних.
Перший, Він же найпростіший, - відсутність залежності , Графічно він виражається у формі прямої, паралельної осі абсцис на графіку, де по осі абсцис (X)відкладено рівні незалежної змінної. Залежна змінна не чутлива до незалежної зміни (див. рис. 4.8).
Монотонно зростаюча залежністьспостерігається тоді, коли збільшення значень незалежної змінної відповідає зміна залежної змінної (див. рис. 4.9).
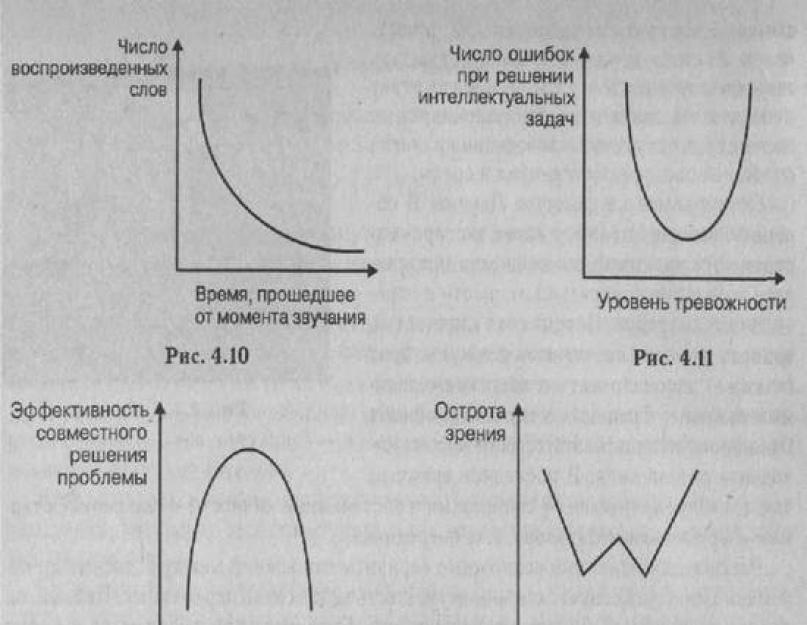
Монотонно спадна залежністьспостерігається, якщо збільшення значень незалежної змінної відповідає зменшення рівня незалежної змінної (див. рис. 4.10).
Нелінійна залежність– U-подібного типу виявляється у більшості експериментів, у яких виявляються особливості психічної регуляції поведінки: (див. рис. 4.11).
Інвертована U-подібна залежністьвиходить у численних експериментальних та кореляційних дослідженнях як у психології особистості, мотивації, так і у соціальній психології (див. рис. 4.12).
Останній варіант залежності виявляється не так часто, як попередні, - складна квазіперіодична залежністьрівня залежної змінної від незалежної (див. рис. 4.13).

При виборі методу опису працює «принцип економії». Будь-який простий опис краще, ніж комплексний, навіть якщо вони однаково успішні. Тому аргументи, поширені у вітчизняних наукових дискусіях на кшталт «Все набагато складніше насправді, ніж представляє автор», щонайменше безглузді. Тим більше, що ніхто не знає, як «насправді».
Так званий «комплексний опис», «багатомірний опис» є часто просто спробою уникнути рішення наукової проблеми, спосіб маскування особистої некомпетентності, яку хочуть приховати за плутаниною кореляційних зв'язків і складені формулами, де все усьому дорівнює.
Мал. 3.1. Різні типи зв'язків між ефективністю діяльності та тривогою
У деяких випадках в експерименті можна зафіксувати не тільки сам факт наявності зв'язку між залежною та незалежною змінними, але й визначити їхній математичний тип. Типи математичних зв'язків між залежною та незалежною змінними дослідники пропонують описувати за допомогою наступних термінів: позитивний лінійний зв'язок, негативний лінійний зв'язок, криволінійний зв'язок, відсутність зв'язку.
Ці типи зв'язків проілюстровані нижче графічно на рис. 3.1 (а), (б), (в), (г) на прикладі вивчення впливу тривоги (незалежна змінна) на ефективність діяльності (залежна змінна).
На рис. 3.2 представлений характер зв'язку між швидкістю сенсомоторної реакції та інтенсивністю сп'яніння (гіпотетичний експеримент).

Мал. 3.2. Характер зв'язку між швидкістю сенсомоторної реакції та алкогольним сп'янінням. Негативний лінійний зв'язок
Побічні змінні
Результати змін, що фіксуються дослідником у залежній змінній, вимагають інтерпретації, основою якої є взаємозв'язок між незалежною та залежною змінними. Ідеально, коли варіювання показників залежної змінної дають можливість чітко та переконливо простежити ефект впливу незалежної змінної. Але, на жаль, існує багато випадків, коли встановити такий взаємозв'язок дуже важко, і він не є однозначним. У такому разі можна підозрювати, що інші фактори, ніж ті, якими намагався маніпулювати експериментатор, вплинули результат експерименту.
Ці фактори також можна кваліфікувати як змінні, тому що вони можуть приймати більш ніж одну шкальну оцінку. їх називають побічними (або додатковими) змінними.
Ми вже згадували одне джерело появи додаткових змінних, саме помилки з вибором піддослідних. Згадувалися три типи таких можливих помилок, що викликають організмові фактори; відношення досліджуваних до експериментальної інструкції та фактори суто ситуативні, які теж впливають на результати експерименту у різних групах.
Побічні змінні певним чином конкурують із незалежною змінною. Ми не завжди можемо знати, чи вплинула на результат саме і змінна, якою ми маніпулювали, чи до цього впливу додалися інші несподівані змінні, що й призвело до того ефекту, який фіксуємо як залежну змінну.
Отже, можливі побічні чинники у психологічному дослідженні необхідно усувати чи зводити до мінімуму. Однак, щоб знати, як це робити, необхідно чітко усвідомити, які з них можуть виступати у ролі побічних. Наприклад, це може бути фактор часу, коли проводиться дослідження (вранці чи ввечері). На ефективність діяльності впливають також пора року, погодні умови.
Іншим джерелом побічних змінних може бути чинник завдання, коли різні умови вимагають різних експериментальних завдань. Наприклад, перевірка гіпотези про вплив змісту певної інформації на ефективність запам'ятовування вимагає відбору різної інформації, оскільки її можна завчити лише один раз.
Але найважливішим джерелом побічних змінних є суб'єктивний фактор, про який ми вже згадували. Індивідуальні особливості діяльності досліджень залежать і від статі, і від віку та стану здоров'я, від культурних особливостей та досвіду. У зв'язку з цим відомий російський дослідник М. Роговін зазначає, що основною принциповою складністю будь-якого психологічного експерименту є забезпечення можливості виділити, простежити та встановити закономірності в динаміці саме тієї змінної, яку треба вивчити. Інакше спостерігатимуться артефакти (небажані ефекти), викликані змішанням незалежних та побічних змінних, коли, за Кепмбеллом, "фон впливає більше, ніж стимул". Тому й існує необхідність ізоляції незалежної змінної та специфічні методи запобігання (або зменшення) впливу додаткових змінних, які ми розглянемо нижче докладніше.
Найчастіше маркетолог шукає відповіді питання типу: «Чи збільшиться показник ринкової частки зі збільшенням кількості дилерів?», «Чи є зв'язок між обсягом збуту і рекламою?» Такі зв'язки не завжди мають причинно-наслідковий характер, а можуть просто статистичну природу. У поставлених питаннях можна безперечно говорити про вплив одного чинника на інший. Однак ступінь впливу факторів, що вивчаються, може бути різною; швидше за все, вплив можуть також якісь інші чинники. Виділяють чотири типи зв'язків між двома змінними: немонотонна, монотонна, лінійна та криволінійна.
Немонотонний зв'язок характеризується тим, що присутність (відсутність) однієї змінної систематично пов'язана з присутністю (відсутністю) іншої змінної, але нічого невідомо про напрям цієї взаємодії (чи призводить, наприклад, збільшення однієї змінної до збільшення або зменшення іншої). Наприклад, відомо, що відвідувачі закусочних вранці воліють замовляти каву, а в середині дня - чай.
Немонотонний зв'язок просто показує, що ранкові відвідувачі вважають за краще також замовляти яйця, бутерброди та бісквіти, а в обідню пору швидше замовляють м'ясні страви з гарніром.
Монотонний зв'язок характеризується можливістю вказати лише загальний напрямок зв'язку між двома змінними без використання будь-яких кількісних характеристик. Не можна сказати, наскільки, наприклад, певне збільшення однієї змінної призводить до збільшення іншої змінної. Існують лише два типи таких зв'язків: збільшення та зменшення. Наприклад, власнику взуттєвого магазину відомо, що дорослі діти зазвичай вимагають взуття більших розмірів. Однак неможливо чітко встановити зв'язок між конкретним віком та точним розміром взуття.
Лінійний зв'язок характеризує прямолінійну залежність між двома змінними. Знання кількісної характеристики однієї змінної автоматично визначає знання величини іншої змінної:
у = а + bх, (4.3)
де у - оцінювана або прогнозована залежна змінна (результативна ознака);
а – вільний член рівняння;
b - коефіцієнт регресії, що вимірює середнє відношення відхилення результативної ознаки від його середньої величини до відхилення факторної ознаки від його середньої величини на одну одиницю його виміру - варіація у, що припадає на одиницю варіації х;
х - незалежна змінна (факторна ознака), що використовується для визначення залежної змінної.
Коефіцієнти а і b розраховуються на основі спостережень величин у їх за допомогою методу найменших квадратів.
Припустимо, що торговий агент продає дитячі іграшки, відвідуючи квартири випадково. Відсутність відвідування якоїсь квартири означає відсутність продажу або а = 0. Якщо в середньому кожен десятий візит супроводжується продажем на 62 долари, то вартість продажу на один візит складе 6,2 долара, або b = 6,2.
у = 0 + 6,2 х.
Таким чином, очікується, що при 100 візитах дохід становитиме 620 доларів. Треба пам'ятати, що ця оцінка не є обов'язковою, а має імовірнісний характер.
Криволінійний зв'язок характеризує зв'язок між змінними, що носить більш складний характер порівняно з прямою лінією. Наприклад, зв'язок між змінними може описуватися 5-подібною кривою (див. розділ 7.3).
Залежно від свого типу зв'язок може бути охарактеризований шляхом визначення: його присутності (відсутності), напряму та сили (тісноти) зв'язку.
Присутність характеризує наявність або відсутність систематичного зв'язку між двома змінними, що вивчаються; вона має статистичну природу. Провівши випробування статистичної значимості визначають, чи існує залежність між даними. Якщо результати дослідження відкидають нульову гіпотезу, це свідчить, що залежність між даними існує.
У разі монотонних лінійних зв'язків останні можуть бути описані з точки зору їхнього напрямку - у бік збільшення чи зменшення.
Зв'язок між двома змінними може бути сильним, помірним, слабким або відсутнім. Сильна залежність характеризується високою ймовірністю існування зв'язку між двома змінними, слабка – малою ймовірністю.
Існують спеціальні процедури визначення зазначених вище характеристик зв'язків. Спочатку треба вирішити, який тип зв'язків може існувати між двома змінними, що вивчаються. Відповідь це питання залежить від обраної шкали вимірів.
Шкала низького рівня (найменувань) може відобразити лише неточні зв'язки, тоді як шкала відносин, або інтервальна, - дуже точні зв'язки. Визначивши тип зв'язку (монотонний, немонотонний), треба встановити, чи існує цей зв'язок для генеральної сукупності в цілому. І тому проводяться статистичні випробування.
Коли знайдено, що з генеральної сукупності існує певний тип зв'язку, встановлюється її напрям. Нарешті необхідно встановити силу (тісноту) зв'язку.
Для визначення, чи існує чи немонотонна залежність, використовується таблиця сполученості двох змінних і критерій хі-квадрат. Як правило, критерій хі-квадрат застосовується для аналізу таблиць сполученості номінальних ознак, проте він може використовуватися і при аналізі взаємозв'язку порядкових або інтервальних змінних. Якщо, скажімо, було з'ясовано, що дві змінні не пов'язані один з одним, їх подальшим дослідженням займатися не варто. Деякі вказівки на зв'язок швидше були зумовлені помилкою вибірки. Якщо ж тест на хі-квадрат вказав на зв'язок, то він існує насправді для генеральної сукупності і його, можливо, слід вивчати. Однак цей аналіз не вказує на характер зв'язку.
Припустимо, що вивчалася лояльність до певної марки пива серед службовців та робітників (двома змінними, виміряними у шкалі найменувань). Результати опитування затабульовані у такому вигляді (табл. 4.16).
Таблиця 4.16
Матриці сполученості частоти
Результати початкової табуляції
Початкові процентні дані (розподіл на 200)

Відсотки по колонках

Перша з наведених матриць містить частоти, що спостерігаються, які порівнюються з очікуваними частотами, що визначаються як теоретичні частоти, що випливають з прийнятої гіпотези про відсутність зв'язку між двома змінними (виконується нульова гіпотеза). Величина відмінності частот, що спостерігаються від очікуваних виражається за допомогою величини х-квадрата. Остання порівнюється з її табличним значенням обраного рівня значимості. Коли величина хі-квадрату мала, то нульова гіпотеза приймається, а отже, вважається, що дві змінні є незалежними і досліднику не варто витрачати час на з'ясування зв'язку між ними, оскільки зв'язок є результатом вибіркової помилки.
Повернемося до нашого прикладу та розрахуємо очікувані частоти, користуючись таблицею частот:
![]() =
=

де f ni - частота, що спостерігається в комірці i;
f ai - очікувана частота в комірці i;
n – число осередків матриці.
З таблиці критичних значень х-квадрату випливає, що для ступеня свободи, що дорівнює нашому прикладі 1, і рівня значущості альфа =0,05 критичне значення х-квадрата дорівнює 3,841 . Видно, що розрахункове значення х-квадрату суттєво більше його критичного значення. Це говорить про існування статистично значущого зв'язку між родом діяльності та лояльністю до дослідженої марки пива, і не тільки для даної вибірки, а й для сукупності загалом. З таблиці слід, що головний зв'язок у тому, що робітники купують пиво цієї марки рідше проти службовцями.
Тіснота зв'язку та його напрямок визначаються шляхом розрахунку коефіцієнта кореляції, який змінюється від -1 до +1. Абсолютна величина коефіцієнта кореляції характеризує тісноту зв'язку, а знак свідчить про її напрям .
Спочатку визначається статистична значущість коефіцієнта кореляції. Безвідносно до його абсолютної величини коефіцієнт кореляції, що не має статистичної значущості, безглуздий. Статистична значимість перевіряється з допомогою нульової гіпотези, яка констатує, що з сукупності коефіцієнт кореляції дорівнює нулю. Якщо нульова гіпотеза відкидається, це означає, що коефіцієнт кореляції для вибірки є значним і його значення для сукупності не буде нульовим. Існують таблиці, за допомогою яких для вибірки певного обсягу можна визначити найменшу величину значущості для коефіцієнта кореляції.
Таблиця 4.17
Сила зв'язку в залежності від величини коефіцієнта кореляції
Розглянемо приклад. Досліджується можливий взаємозв'язок між сумарними продажами компанії на окремих двадцяти територіях та кількістю збутовиків, які здійснюють ці продажі. Були розраховані середні величини продажу та середні квадратичні відхилення. Середня величина продажів становила 200 мільйонів доларів, а середнє квадратичне відхилення – 50 мільйонів доларів. Середня кількість збутовиків дорівнювала 12 при середньому квадратичному відхиленні, що дорівнює 4. Для стандартизації отриманих чисел з метою проведення уніфікованих порівнянь обсяги продажів у кожному регіоні переводяться у величини середніх квадратичних відхилень від середньої величини для всіх регіонів (шляхом віднімання обсягу продажів для кожного регіону з середнього для регіонів обсягу продажу та розподілу отриманих величин на середнє квадратичне відхилення). Такі ж розрахунки проводять і для збутовиків, які обслуговують різні регіони (рис. 4.7). З рис. 4.7 видно, що дві лінії змінюються так. Це говорить про позитивний, дуже тісний зв'язок двох досліджуваних змінних.

Мал. 4.7. Кореляція між числом збутовиків та обсягами продажів
Вихідні дані в аналізованому прикладі також можна по-іншому (рис. 4.8). З рис. 4.8 витікають відносно слабкий розкид точок (якби всі вони лягли на одну лінію, коефіцієнт кореляції дорівнював +1) і досить великий кут нахилу уявної кривої, проведеної через ці точки, що говорить про сильний вплив чисельності збутовиків на обсяг продажів.

Види взаємозв'язків між ознаками. 3
Коефіцієнт кореляції. 8
Коефіцієнт кореляції Браве-Пірсона. 11
Обмеження використання коефіцієнта кореляції. 13
Перевірка важливості кореляції. 14
Рангова кореляція. 15
Множинна кореляція. 16
Бібліографічний список. 20
Види взаємозв'язків між ознаками
Ще Гіппократ звернув увагу на те, що між статурою та темпераментом людей, між будовою їх тіла та схильністю до захворювань існує певний зв'язок.
Найчастіше розглядаються найпростіші ситуації, коли в ході дослідження вимірюють значення лише однієї ознаки генеральної сукупності, що варіює. Інші ознаки або вважаються постійними для цієї сукупності, або належать до випадкових факторів, що визначають варіювання досліджуваного ознаки. Як правило, дослідження у спорті значно складніші і мають комплексний характер. Наприклад, при контролі за перебігом тренувального процесу вимірюється спортивний результат, і одночасно може оцінюватися цілий ряд біомеханічних, фізіологічних, біохімічних та інших параметрів (швидкість та прискорення загального центру мас та окремих ланок тіла, кути в суглобах, сила м'язів, показники систем дихання та кровообігу) , обсяг фізичного навантаження та енерговитрати організму на її виконання тощо). У цьому часто виникає питання взаємозв'язку окремих ознак. Наприклад, як залежить спортивний результат деяких елементів техніки спортивних рухів? як пов'язані енерговитрати організму з обсягом фізичного навантаження певного виду? наскільки точно за результатами виконання деяких стандартних вправ можна судити про потенційні можливості людини у конкретному виді спортивної діяльності? і т. п. У всіх цих випадках увагу дослідника привертає залежність між різними величинами, що описують цікаві для нього ознаки.
Цій меті служить математичне поняття функції, що має на увазі випадки, коли певному значенню однієї (незалежної) змінної Х, званої аргументом
відповідає певне значення іншої (залежної) змінної Y, званої функцією
. Однозначна залежність між змінними величинами Yі Xназивається функціональною
, тобто. Y = f(X)(“Ігрек є функція від ікс”).
Наприклад, у функції Y = 2X
кожному значенню Xвідповідає вдвічі більше значення Y. У функції Y = 2X 2
кожному значенню Yвідповідає 2 певних значення X.
Але такого роду однозначні чи функціональні зв'язки між змінними величинами зустрічаються не завжди. Відомо, наприклад, що між зростанням (довжиною тіла) і масою людини існує позитивний зв'язок: вищі індивіди мають зазвичай і більшу масу, ніж індивіди низького зростання. Те саме спостерігається і щодо якісних ознак: блондини, як правило, мають блакитні, а брюнети – карі очі. Однак з цього правила є винятки, коли порівняно низькорослі індивіди виявляються важчими за високорослі, і серед населення хоча і нечасто, але зустрічаються кароокі блондини і блакитноокі брюнети. Причина таких “виключень” у цьому, кожен біологічний ознака, висловлюючись математичною мовою, є функцією багатьох змінних; на його величині позначається вплив і генетичних та середовищних факторів, у тому числі і випадкових, що спричиняє варіювання ознак. Звідси залежність між ними набуває не функціонального, а статистичний характер
, коли певному значенню однієї ознаки, що розглядається як незалежна змінна, відповідає не одне і те ж числове значення, а ціла гамма розподіляються в варіаційний ряд числових значень іншої ознаки, що розглядається як незалежна змінна. Така залежність між змінними величинами називається кореляційної
або кореляцією
(Термін "кореляція" походить від лат. correlatio - Співвідношення, зв'язок). При цьому даний вид взаємозв'язку між ознаками проявляється в тому, що при зміні однієї із величин змінюється середнє значення іншої.
Якщо функціональні зв'язки однаково легко виявити і одиничних, і групових об'єктах, цього не можна сказати про кореляційних зв'язках, які вивчаються лише з групових об'єктах методами математичної статистики.
· Чи існує зв'язок між досліджуваними змінними?
· Як виміряти тісноту зв'язків?
Загальна схема взаємозв'язку параметрів під час статистичного дослідження наведено на рис. 1.
Рис 1. Взаємозв'язок параметрів під час статистичного дослідження
На малюнку S – модель досліджуваного реального об'єкта, що пояснюють (незалежні, факторні) змінні описують умови функціонування об'єкта. Випадкові чинники – це чинники, вплив яких важко врахувати чи впливом яких зараз нехтують. Результати (залежні, пояснювані) змінні характеризують результат функціонування об'єкта.
Вибір способу аналізу взаємозв'язку здійснюється з урахуванням природи аналізованих змінних.
Кореляція– це статистична залежність між випадковими величинами, коли він зміна однієї з випадкових величин призводить до зміни математичного очікування інший.
Розрізняють парну, приватну та множинну кореляцію.
Парна кореляція– це зв'язок між двома ознаками (результативним та факторним або між двома факторними).
Приватна кореляція– це зв'язок між двома ознаками (результативною та факторною або між двома факторними) при фіксованому значенні інших факторних ознак.
Множинна кореляція– це зв'язок між результативним та двома або більше факторними ознаками, включеними до дослідження.
Залежно від кількості ознак, включених у модель, кореляційний зв'язок може бути однофакторним (або парним) і багатофакторним (або множинним) .
Кореляційний аналіз- Це розділ математичної статистики, присвячений вивченню взаємозв'язків між випадковими величинами. Кореляційний аналіз полягає у кількісному
Завдання кореляційного аналізу зводиться до встановлення напряму та форми зв'язку між ознаками, вимірювання її тісноти та оцінки достовірності вибіркових показників кореляції.
Кореляційний зв'язок між ознаками може бути лінійної та криволінійної (нелінійної), позитивної та негативної.
Пряма кореляція відображає однотипність у зміні ознак: зі збільшенням значень першої ознаки збільшуються значення та іншої, або зі зменшенням першої зменшується другою.
Зворотня кореляціявказує на збільшення першої ознаки при зменшенні другої або зменшення першої ознаки при збільшенні другої.
Наприклад, більший стрибок та більша кількість тренувань – пряма кореляція, зменшення часу, витраченого на подолання дистанції, та більша кількість тренувань – зворотна кореляція.
Кореляція вивчається на підставі експериментальних даних, що є виміряними значеннями ( x i , y i) двох ознак. Якщо експериментальних даних небагато, то двовимірний емпіричний розподіл подається у вигляді подвійного ряду значень x iі y i. У цьому кореляційну залежність між ознаками можна описувати різними способами. Відповідність між аргументом та функцією може бути задана таблицею, формулою, графіком тощо.
Кореляційний аналіз, як і інші статистичні методи, заснований на використанні імовірнісних моделей, що описують поведінку досліджуваних ознак у деякій генеральній сукупності, з якої отримано експериментальні значення x iі y i.
Коли досліджується кореляція між кількісними ознаками, значення яких можна точно виміряти в одиницях метричних шкал (метри, секунди, кілограми і т.д.), дуже часто приймається модель двовимірної нормально розподіленої генеральної сукупності. Така модель відображає залежність між змінними величинами x iі y i графічно як геометричного місця точок у системі прямокутних координат. Цю графічну залежність називають також діаграмою розсіюванняабо кореляційним полем
.
При дослідженні кореляції використовуються графічний та аналітичний підходи.
Графічний аналіз починається з побудови кореляційного поля. Кореляційне поле (або діаграма розсіювання) є графічною залежністю між результатами вимірів двох ознак. Для її побудови вихідні дані наносять на графік, відображаючи кожну пару значень (xi, yi) у вигляді точки з координатами xi та yi у прямокутній системі координат.
Візуальний аналіз кореляційного поля дозволяє зробити припущення про форму та напрям взаємозв'язку двох досліджуваних показників. За формою взаємозв'язку кореляційні залежності прийнято розділяти на лінійні (див. рис. 2) та нелінійні (див. рис. 3). При лінійній залежності загальна кореляційного поля близька до еліпса. Лінійний взаємозв'язок двох випадкових величин полягає в тому, що при збільшенні однієї випадкової величини інша випадкова величина має тенденцію зростати (або зменшуватися) за лінійним законом.


Рис 2. Лінійний статистичний зв'язок Рис 3. Нелінійний статистичний зв'язок
Напрямок зв'язку є позитивним, якщо збільшення значення однієї ознаки призводить до збільшення значення другої (див. рис. 4) і негативним, якщо збільшення значення однієї ознаки призводить до зменшення значення другої (див. рис. 5).
Залежності, мають лише позитивні чи лише негативні спрямованості, називаються монотонними.
Коефіцієнт кореляції
Кількісна оцінка тісноти взаємозв'язку двох випадкових величин здійснюється з допомогою коефіцієнта кореляції. Вид коефіцієнта кореляції і, отже, алгоритм його обчислення залежать від шкали, в якій виробляються вимірювання показників, що вивчаються, і від форми залежності.
Значення коефіцієнта кореляції може змінюватися в діапазоні від -1 до +1:
Абсолютне значення коефіцієнта кореляції свідчить про силу взаємозв'язку. Чим менше його абсолютне значення, тим слабший зв'язок. Якщо він дорівнює нулю, зв'язок взагалі відсутній. Чим більше значення модуля коефіцієнта кореляції, тим більше зв'язок і тим менше розкид у значеннях при кожному фіксованому значенні . Знак коефіцієнта кореляції визначає спрямованість взаємозв'язку: мінус – негативна, плюс – позитивна (див. рис. 6).
 |  |  |  |
 |  |  |  |
 |  |  |
Рис.6. Кореляційні поля за різних значень коефіцієнта кореляції

Рис.7. Коефіцієнти кореляції за різної форми кореляційного поля.
Коефіцієнт кореляції відбиває лінійну залежність і зовсім підходить для описи складних, нелінійних залежностей (нижній рядок).
Досить умовно можна використовувати наступна класифікація взаємозв'язків за значенням коефіцієнта кореляції (див. табл. 1).
Таблиця 1. Інтерпретація значень коефіцієнт кореляції
Залежна змінна не чутлива до змін незалежної.
Монотонно зростаюча залежність: збільшення значень незалежної змінної відповідає зміна залежної змінної.
Монотонно спадна залежність: збільшенню значень незалежної змінної відповідає зменшення рівня залежної змінної.
Аналітична форма залежності між парою, що вивчається
ознак (регресійна функція) визначається за допомогою
наступних методів:
1) з урахуванням візуальної оцінки характеру связи. На ліній $
ном графіку по осі абсцис відкладаються значення фактор$
ного (незалежного) ознаки x, по осі ординат - значення
результативної ознаки y. На перетині відповідаю$
ших значень відзначаються точки. Отриманий точковий гра$
фік у зазначеній системі координат називається кореляційним $
ним полем. При з'єднанні отриманих точок виходить
емпірична лінія, на вигляд якої можна судити не тільки
про наявність, але й про форму залежності між досліджуваними пе$
ремінними;
3.Економічні моделі та типи статистичних даних, що використовуються в них
До найпоширеніших економетричних моделей належать:
моделі споживчого та ощадного споживання;
моделі взаємозв'язку ризику та прибутковості цінних паперів;
моделі пропозиції праці;
макроекономічні моделі (модель зростання);
моделі інвестицій;
маркетингові моделі;
моделі валютних курсів та валютних криз та ін.
Статистичні та математичні моделі економічних явищ і процесів визначаються специфікою тієї чи іншої галузі економічних досліджень. Так, в економіці якості моделі, на яких засновані статистичні методи сертифікації та управління якістю - моделі статистичного приймального контролю, статистичного контролю (статистичного регулювання) технологічних процесів (зазвичай за допомогою контрольних карток Шухарта або кумулятивних контрольних карток), планування експериментів, оцінки та контролю надійності та інші - використовують як технічні, і економічні характеристики, тому ставляться до економетриці, як і багато моделей теорії масового обслуговування (теорії черг). Економічний ефект лише від використання статистичного контролю у промисловості США оцінюється як 0,8 % валового національного продукту (20 мільярдів доларів на рік), що значно більше, ніж від будь-якого іншого економіко-математичного чи економетричного методу.
Кожній галузі економічних досліджень, пов'язаних з аналізом емпіричних даних, як правило, відповідають свої економетричні моделі. Наприклад, для моделювання процесів оподаткування з метою оцінки результатів застосування впливів, що управляють (наприклад, зміни ставок податків) на процеси оподаткування повинен бути розроблений комплекс відповідних економетричних моделей. Крім системи рівнянь, що описує динаміку системи оподаткування під впливом загальної економічної ситуації, керуючих впливів та випадкових відхилень, необхідний блок експертних оцінок. Корисний блок статистичного контролю, що включає як методи вибіркового контролю правильності сплати податків (податкового аудиту), і блок виявлення різких відхилень параметрів, що описують роботу податкових служб. Підходам до проблеми математичного моделювання процесів оподаткування присвячена монографія, що містить також інформацію про сучасні статистичні (економетричні) методи та економіко-математичні моделі, у тому числі імітаційні.
За допомогою економетричних методів слід оцінювати різні величини та залежності, які використовуються при побудові імітаційних моделей процесів оподаткування, зокрема функції розподілу підприємств за різними параметрами податкової бази. При аналізі потоків платежів необхідно використовувати економетричні моделі інфляційних процесів, оскільки без оцінки індексу інфляції неможливо обчислити дисконт-функцію, тому не можна встановити реальне співвідношення авансових і «підсумкових» платежів.
Прогнозування збору податків може здійснюватися за допомогою системи тимчасових рядів - на першому етапі за кожним одновимірним параметром окремо, а потім - за допомогою деякої лінійної економетричної системи рівнянь, що дає можливість прогнозувати векторний параметр з урахуванням зв'язків між координатами та лагами, тобто впливу значень змінних у певні попередні моменти часу. Можливо, більш корисними виявляться імітаційні моделі більш загального виду, що базуються на інтенсивному використанні сучасної обчислювальної техніки.
4. Основні етапи економетричного моделювання
Виділяють сім основних етапів економетричного моделювання:
1) постановочний етап, у процесі здійснення якого визначаються кінцеві цілі та завдання дослідження, а також сукупність включених до моделі факторних та результативних економічних змінних. При цьому включення до економетричної моделі тієї чи іншої змінної має бути теоретично обґрунтовано і не повинно бути занадто великим. Між факторними змінними не повинно бути функціонального чи тісного кореляційного зв'язку, тому що це призводить до наявності в моделі мультиколлінеарності та негативно позначається на результатах всього процесу моделювання;
2) апріорний етап, у процесі здійснення якого проводиться теоретичний аналіз сутності досліджуваного процесу, а також формування та формалізація відомої до початку моделювання (апріорної) інформації та вихідних припущень, що стосуються зокрема природи вихідних статистичних даних та випадкових залишкових складових у вигляді низки гіпотез;
3) етап параметризації (моделювання), у процесі здійснення якого вибирається загальний вигляд моделі і визначається склад і форми зв'язків, що входять до неї, тобто відбувається безпосередньо моделювання.
До основних завдань етапу параметризації відносяться:
а) вибір найбільш оптимальної функції залежності результативної змінної від факторних змінних. При виникненні ситуації вибору між нелінійною та лінійною функціями залежності, перевага завжди віддається лінійній функції, як найбільш простий та надійний;
б) завдання специфікації моделі, до якої входять такі підзавдання, як апроксимація математичною формою виявлених зв'язків та співвідношень між змінними, визначення результативних та факторних змінних, формулювання вихідних передумов та обмежень моделі.
4) інформаційний етап, у процесі здійснення якого відбувається збирання необхідних статистичних даних, а також аналізується якість зібраної інформації;
5) етап ідентифікації моделі, у ході здійснення якого відбувається статистичний аналіз моделі та оцінювання невідомих параметрів. Даний етап безпосередньо пов'язаний з проблемою ідентифікованості моделі, тобто відповіді на запитання «Чи можливо відновити значення невідомих параметрів моделі за наявними вихідними даними відповідно до рішення, прийнятого на етапі параметризації?». Після позитивної відповіді це питання вирішується проблема ідентифікації моделі, т. е. реалізується математично коректна процедура оцінювання невідомих параметрів моделі за наявними вихідними даними;
6) етап оцінки якості моделі, у ході здійснення якого перевіряється достовірність та адекватність моделі, тобто визначається, наскільки успішно вирішені завдання специфікації та ідентифікації моделі, яка точність розрахунків, отриманих на її основі. Побудована модель
має бути адекватною реальному економічному процесу. Якщо якість моделі є незадовільною, відбувається повернення до другого етапу моделювання;
7) етап інтерпретації результатів моделювання.
№5 Економетричний аналіз виробничого процесу
Розглядаючи економетричне дослідження загалом, у ньому можна назвати такі этапы:
1. Постановка проблеми, тобто визначення мети та завдань дослідження, виділення залежних (уj) та незалежних (xk) економічних змінних на основі якісного аналізу взаємозв'язків, що вивчаються, методами економічної
2. Збір необхідних вихідних даних.
3. Побудова економетричної моделі та оцінка її адекватності та ступеня відповідності вихідним даним.
4. Використання моделі з метою аналізу та прогнозування параметрів досліджуваного явища.
5. Якісна та кількісна інтерпретація отриманих на основі моделі результатів.
6. Практичне використання результатів. У процесі економічної інтерпретації результатів слід відповісти на такі питання: 12
- Чи є статистично значущими пояснювальні фактори, важливі з теоретичної точки зору?
– чи відповідають оцінки параметрів моделі якісним уявленням?
№6. Парний регресійний аналіз
Регресією в теорії ймовірностей та математичної статистики прийнято називати залежність середнього значення будь-якої величини (y) від деякої іншої величини або від кількох величин (хi).
Парною регресією називається модель, що виражає залежність середнього значення залежної змінної y від однієї незалежної змінної х
де у – залежна змінна (результативна ознака); х – незалежна,
пояснювальна змінна (ознака-фактор).
Парна регресія застосовується, якщо є домінуючий фактор, що зумовлює велику частку зміни змінної, що вивчається пояснюється, який і використовується в якості пояснюючої змінної.
Множинною регресією називають модель, що виражає залежність середнього значення залежної змінної y від кількох незалежних змінних х1, х2, …, хp
ŷ = f (x1, x2, ..., xp).
Класична нормальна модель лінійної множинної регресії.
По виду аналітичної залежності розрізняють лінійні та нелінійні регресії.
Лінійна парна регресія описується рівнянням: ŷ=a+bx
Якщо між економічними явищами існують нелінійні співвідношення, то вони виражаються за допомогою відповідних нелінійних функцій: наприклад, рівносторонньої гіперболи, параболи другого ступеня та д.р.
№7. . Лінійна парна регрессія. Визначення параметрів рівняння регресії
Лінійна парна регресія описується рівнянням: ŷ=a+bx, згідно з яким зміна Δy змінної y прямопропорційно до зміни Δx змінної x (Δy = b·Δx). Для оцінки параметрів a та b рівняння регресії (2.6) скористаємося методом найменших квадратів (МНК). За певних припущень щодо помилки ε МНК дає найкращі оцінки параметрів лінійної
моделі. Модель парної лінійної регресії: y = a + b * x + u (y - залежна змінна, a + b * x - невипадкова складова, х - незалежна змінна, u - випадкова складова)
1 | | | | | | | |



